Installing Anaconda and Jupyter notebook
Installing Anaconda and jupyter notebook
Anaconda
- 자신의 환경과 맞는 버전을 설치.
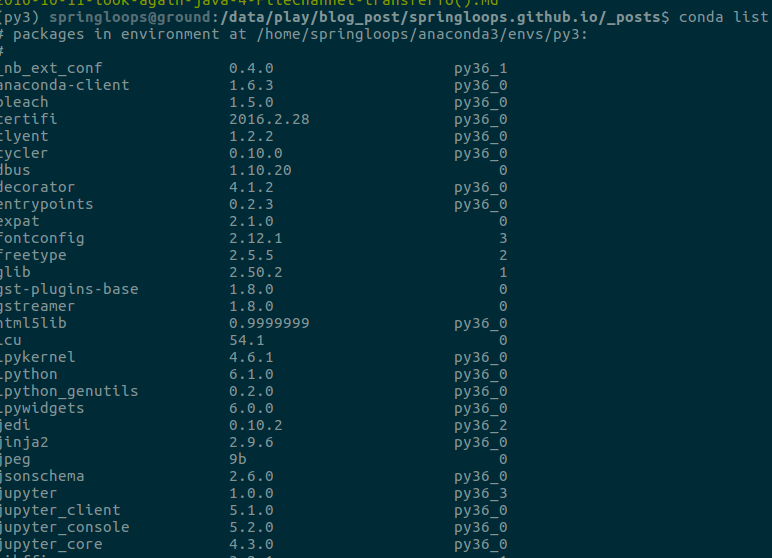
- 기본 conda 환경에 설치된 패키지 조회
conda list
conda 환경 생성
conda create -n [virtualenv_name] [python=version]
conda create -n py3 python=3
conda 환경 조회
conda env list

가상 환경 접속
source activate [virturalenv_name]
source activate py3
가상환경 내 패키지 설치하기
conda install [package]
conda install jupyter notebook
가상 환경내 설치된 패키지 확인
conda list
가상 환경 설정 내보내기
공유 등을 위해..
conda env export > environment.yaml
환경 설정 파일 (environment.yaml) 기반으로 환경 생성하기
환경 설정 파일 (*.yaml) 의 첫번째 라인에 있는 name 에 정의된 값으로 환경 이름이 결정된다.
conda env create -f environment.yaml
가상 환경 나오기
source deactivate
가상 환경 삭제하기
conda env remove -n [virtualenv_name]
conda env remove -n py3
jupyter notebook 을 실행한 상태에서 slideshow 만들기
jupyter nbconvert 명령 실행
jupyter nbconvert --to slides 2017-11-03-conda-with-jupyter-notebook.ipynb --to slides --post serve
jupyter notebook
오프라인에서 사용가능한 slideshow 만들기
reveal.js 설치
- 원하는 위치에 다운로드
git clone https://github.com/hakimel/reveal.js.git - jupyter notebook cell 에 slide 설정
-
View > Cell Toolbar > Slideshow 선택
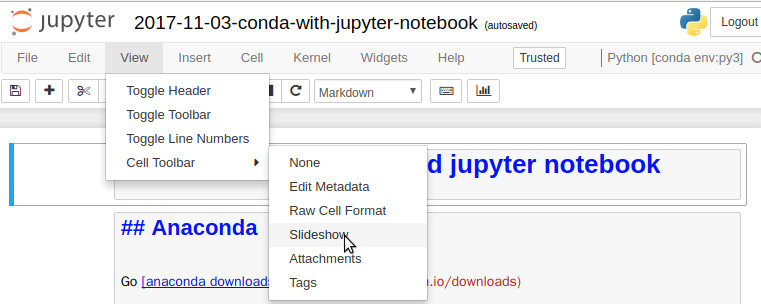
-
Slide Type 설정

-
jupyter nbconvert 명령 실행
jupyter nbconvert --to slides 2017-11-03-conda-with-jupyter-notebook.ipynb --reveal-prefix=/data/play/reveal.js
springloops
Steady Developer






Newest Posts
- [정리] 정보이론: 정보량 (Information), 엔트로피 ( Entropy ), 쿨백 라이블러 발산 (KL-Divergence), 크로스 엔트로피 ( Cross - Entropy ), maximum likelihood
- [발번역] Bag of words (BoW) - Natural Language processing
- Installing Anaconda and Jupyter notebook
- 다시 보는 Java : FileChannel transferTo()
- 다시 보는 Java : NIO Channel
- 다시 보는 Java : Socket-Direct-Protocol
- 다시 보는 Java
- Streamsets DataCollector Source Build
- Apache Helix Core Concepts
- Introduce Flipkart Aesop
Tag Cloud
4.0 (1)
Aesop (1)
Apache (2)
BIGDATA (1)
Bag of Words (1)
BoW (1)
CDC (7)
Centos (1)
Channel (1)
DOC (1)
DataCollector (1)
Database (1)
Databus (6)
Distributed (1)
Elevation (1)
FAQ (1)
FileChannel transferTo (1)
Head First (3)
Hive (1)
Import (1)
Information (1)
JDBC (1)
JNI (2)
JS (1)
Java (10)
JavaScript (2)
KL Divergence (1)
Kafka (4)
Lambda (1)
Lambda Architecture (1)
LinkedIn (6)
Linux (2)
MQ (1)
Monitoring (1)
NG (3)
NIO (2)
NIO Channel (1)
Network (1)
Nimbus (1)
Open API (2)
Open Source (6)
Python (1)
QueryElevationComponent (1)
Raspberry Pi (1)
Real Time (1)
SDP (1)
Score (1)
Sockets Direct Protocol (1)
Statistics (3)
Storm (4)
Storm master woker (1)
Streamsets (1)
Streamsets DataCollector (1)
Struts (2)
Summary (3)
TIP (1)
Tutorial (1)
WORKER (1)
Wiki (3)
XAuth (1)
XQuery (1)
anaconda (1)
android.mk (1)
apache Helix (1)
apache flume (3)
apache kafka (2)
apache spark (2)
architecture (1)
autocomplete (1)
backup (2)
blkid (1)
build (1)
builder (3)
cassandra (3)
cassandra h/w (1)
cassandra hardware (1)
cassandra remote client (1)
cassandra troubleshooting (1)
cassandra warning (1)
cloud (1)
collaborative filtering (1)
cross entropy (1)
data import (1)
databus (1)
db indexing (1)
dead letter exchange (1)
distributed search (2)
dlx (1)
docker (1)
entropy (1)
fdisk (1)
flipkart (1)
flipkart Aesop (1)
flume (3)
flume ng (3)
fq (1)
framework (5)
fstab (1)
function (1)
function query (2)
gradle (3)
hadoop (5)
hadoop + solr (1)
hadoop integration solr (1)
hadoop+solr (1)
hashing trick (1)
head first statistics (3)
hive begins (1)
hive tutorial (1)
hive 소개 (1)
iBATIS (3)
index (3)
index backup (1)
index replication (1)
indexing (4)
integration (2)
introduce (1)
java (7)
java Troubleshooting (1)
java monitoring (1)
javascript object (1)
javascript 접근자 (1)
jupyter (1)
kafka document (1)
kafka introduction (1)
katta (3)
katta hadoop (1)
katta install (1)
koreanAnalyzer (1)
koreanAnalyzer 4.0 (1)
load test (1)
look again (4)
lucene (5)
lucene + hadoop (1)
lucene 4.0 (1)
lucene 4.0 한글 analyzer (1)
lucene 4.1 (1)
machine learning (1)
master (1)
maximum liklihood (1)
memcached (1)
memory (1)
mount (1)
multi mechanize (1)
multiindex (1)
oauth (1)
opensource (14)
oracle (1)
predictionIO (1)
rabbitmq (1)
recommendation system (1)
replication (1)
search (1)
server load (1)
shard (1)
shark shell (1)
similarity algorithm (1)
slideshare (1)
sola admin (1)
solr (21)
solr + hadoop (4)
solr 4.0 (3)
solr 4.1 (1)
solr backup (1)
solr cloud (1)
solr distributed (1)
solr index backup (1)
solr indexing (1)
solr shard (1)
solr tip (1)
solr wiki (2)
solr 한글 analyzer (1)
solr4.0 (1)
solrcloud (2)
solrcolud (1)
sort (4)
sortMissingFirst (1)
sortMissingLast (1)
spark (2)
spark cluster (1)
spout (1)
storm master node (1)
storm spout (1)
storm wokrer node (1)
storm 구성 (2)
storm 마스터 노드 (1)
storm 워커 노드 (1)
storm 정의 (2)
storm kafka (2)
suggeest (1)
suggester (1)
supervisor (1)
tf idf (1)
tomcat (2)
tomcat configuration (1)
tomcat tuning (1)
tomcat7 (2)
tools (10)
transferTo (1)
troubleshooting (2)
tuning (1)
tutorial (1)
ubuntu10.04 (1)
ubuntu10.04 network (1)
vert.x (1)
xdk (1)
검색 점수 (1)
계획 (1)
낙서 (1)
당신 인생 한 모퉁이에 나를 (1)
도커 (1)
도커 소개 (1)
람다 (1)
람다 아키텍처 (1)
루씬 (1)
마스터 노드 (1)
발 번역 (4)
번역 (2)
복제 (1)
부하 (1)
분석 (5)
세계문학전집 (1)
스트럿츠 (2)
쏠라 (1)
아이바티스 (3)
아파치 카프카 (1)
아파치 플럼 (2)
에쿠니 가오리 (2)
올리기 (1)
워커 노드 (1)
유사도 알고리즘 (1)
일기 (1)
젊은 베르테르의 슬픔 (1)
제비꽃 설탕절임 (1)
추천시스템 (1)
카산드라 (2)
카산드라 문제 (1)
카산드라 설치 문제 (1)
카산드라 워닝 (1)
카산드라 원격접속 (1)
카산드라 해결 (1)
카타 (2)
카타 설치 (1)
카프카 (1)
태그를 입력해 주세요. (1)
통계 (3)
통계학 (3)
특정 문서 (1)
플럼 (2)
플럼 ng (2)
하둡 (1)
하드웨어 (1)
한 글자 오류 (1)
한 글자 형태소 분석 (1)
한글자 오류 (1)
한글자 형태소 분석 (1)
헤드 퍼스트 (3)
헤드 퍼스트 통계학 (3)
협업 필터링 (1)