Lambda Architecture 요약 정리
Nathan Marz 의 포스팅 http://www.databasetube.com/database/big-data-lambda-architecture/ 에 대한 요약.
Lambda Architecture 요약
-
실시간으로 임의의 데이터 셋에서 임의의 함수를 계사하는 것은 어려운 문제이다.
-
완벽한 솔류션을 제공하는 하나의 툴은 없고, 대신 다양한 툴과 빅데이터 기술을 사용하여 처리 해야 한다.
-
람다 아키텍처는 임의의 데이터 셋에 대한 임의의 함수를 계산하는 문제를 해결한다.
Lambda Architecture 구성
Lambda Architecure는 세 계층으로 이루어져 있다.
-
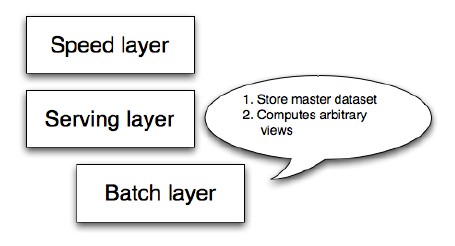
Batch layer
-
Serving layer
-
Speed layer
Batch layer
데이터를 미리 계산하고 계산 결과를 제공한다.
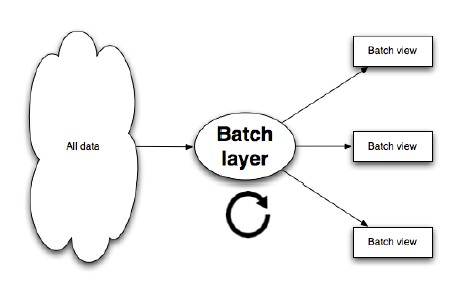
Batch layer 의 조건
Batch Layer 는 두가지 작업을 수행 할 수 있어야 한다.
-
끊임 없이 증가 하는 마스터 데이터 셋의 불변 저장
-
그 데이터에 대한 임의의 함수 계산
Tool ex) Hadoop
Serving layer
Batch layer의 결과 데이터에 대해 질의를 하기 위해, 결과 데이터를 로드하고 질의 할 수 있도록 제공하는 레이어
-
batch view 를 색인한다.
-
batch view 에 대해 효율적으로 특정 값을 얻기 위한 쿼리를 할 수 있다.
-
batch view 에서 로드된 전문 분산 데이터 베이스
-
그들에게 쿼리 할 수 있고, 계속적으로 batch layer 에서 계산된 결과를 교환 한다.
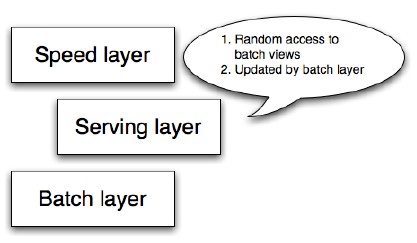
Serving layer 의 필요성
ex) batch 결과가 pageview 데이터에 대한 [시간당, url] 건수 일 경우, batch view는 본질적으로 단순한 flat file 이다.
그것은 빠르게 특정 url 에 대한 값을 가져 올 수 없다.
Serving layer 의 조건
-
Serving layer 데이터베이스는 일괄 업데이트가 가능해야 한다.
-
Random Read 필요.
-
Random Write는 불필요
중요 !
Random Write는 대부분 데이터베이스의 복잡도를 높이는 원인이기 때문임.
Random Write를 제공하지 않는 Serving layer 데이터베이스는 매우 단순할 수 있다.
단순함은 강력하게 만들고, 예측, 설정이 쉽고, 운영이 쉽다.
Tool ex) ElephantDB - (저자가 만든 Serving layer 데이터베이스. 저자는 twitter 엔지니어로, storm 을 만들었다….)
ex) batch 결과가 pageview 데이터에 대한 시간당/ url 건수 일 경우, batch view는 본질적으로 단순한 flat file 이다.
그것은 빠르게 특정 url 에 대한 값을 가져 올 수 없다.
Speed layer
위 두가지 layer 는 낮은 대기시간 업데이트 문제가 해결되지 않는다. (배치 와 데이터 로드에 걸리는 시간 때문에)
Steady Developer






- [정리] 정보이론: 정보량 (Information), 엔트로피 ( Entropy ), 쿨백 라이블러 발산 (KL-Divergence), 크로스 엔트로피 ( Cross - Entropy ), maximum likelihood
- [발번역] Bag of words (BoW) - Natural Language processing
- Installing Anaconda and Jupyter notebook
- 다시 보는 Java : FileChannel transferTo()
- 다시 보는 Java : NIO Channel
- 다시 보는 Java : Socket-Direct-Protocol
- 다시 보는 Java
- Streamsets DataCollector Source Build
- Apache Helix Core Concepts
- Introduce Flipkart Aesop